
A、ResultSet接口被用来提供访问查询结果的数据表,查询结果被当作ResultSet对象而返回。
B、ResultSet对象提供“指针”,指针每次访问数据库表的一行。
C、ResultSet的next()方法用来移动指针到数据表的下一行,如果到达表尾,next()方法返回假的布尔值-false,否则为真。
D、ResultSet接口提供大量的获得数据的方法,这些方法返回数据表中任意位置的数据。
E、以上说法都不对
●试题三
阅读下列说明和C代码,将应填入(n)处的字句写在答题纸的对应栏内。
【说明】
本题给出四个函数,它们的功能分别是:
1.int push(PNODE *top,int e)是进栈函数,形参top是栈顶指针的指针,形参e是入栈元素。
2.int pop(PNODE *top,int *e)是出栈函数,形参top是栈顶指针的指针,形参e作为返回出栈元素使用。
3.int enQueue(PNODE *tail,int e)是入队函数,形参tail是队尾指针的指针,形参e是入队元素。
4.int deQueue(PNODE *tail,int *e)是出队函数,形参tail是队尾指针的指针,形参e作为返回出队元素使用。
以上四个函数中,返回值为0表示操作成功,返回值为-1表示操作失败。
栈是用链表实现的;队是用带有辅助结点(头结点)的单向循环链表实现的。两种链表的结点类型均为:
typedef struct node{
int value;
struct node *next;
}NODE,*PNODE;
【函数1】
int push(PNODE *top,int e)
{
PNODE p=(PNODE)malloc (sizeof(NODE));
if (!p) return-1;
p-> value =e;
(1) ;.
*top=p;
return 0;
}
【函数2】
int pop (PNODE *top,int *e)
{
PNODE p=*top;
if(p==NULL)return-1;
*e=p->value;
(2) ;
free(p);
return 0;
}
【函数3】
int enQueue (PNODE *tail,int e)
{PNODE p,t;
t=*tail;
p=(PNODE)malloc(sizeof(NODE));
if(!p)return-l;
p->value=e;
p->next=t->next;
(3) ;
*tail=p;
return 0;
}
【函数4】
int deQueue(PNODE *tail,int *e)
{PNODE p,q;
if((*tail)->next==*tail)return -1;
p=(*tail)->next;
q=p->next;
*e=q->value;
(4) =q->next;
if(*tail==q) (5) ;
free(q);
return 0;
}
●试题三
【答案】(1)p->next=*top(2)*top=p->next或*top=(*top)->next
(3)t->next=p或(*tail)->next=p(4)p->next或(*tail)->next->next
(5)*tail=p或*tail=(*tail)->next
【解析】(1)插入结点p后,p应当指向插入前头结点,所以填入p->next=*top。(2)出栈后,头指针应指向它的下一结点,所以填入*top=p->next或*top=(*top)->next。(3)入队时,需要将结点插入队尾,所以应当填入(*tail)->next=p或t->next=p(t也指向尾结点)。(4)出队时,需要删除队头结点,通过(*tail)->next可以得到对队头结点的引用。(4)处是正常删除队头结点的情况,空格处应填入头结点指向下一结点的指针,即p->next或(*tail)->next->next。(5)处是需要考虑的特殊情况,即队列中最后一个元素出队后,要更新队尾指针,即填入*tail=p或*tail=(*tail)->next。
下列的说法中,不正确的是()
A.迭代器协议是指:对象必须提供一个next方法
B.list、dict、str虽然是Iterable,却不是Iterator
C.生成器与迭代器对象的区别在于:它仅提供next()方法
D.生成器实现了迭代器协议,但生成器是边计算边生成达到节省内存及计算资源
Python内置函数__________可以返回列表、元组、字典、集合、字符串以及range对象中元素个数。
Python内置函数__________用来返回序列中的最小元素。
北京合众思壮科技股份有限公司2月招聘面试题面试题面试官常问到的一些题目整理如下:问题 Q1:迭代器和生成器的区别?可用的回答 : 1)迭代器是一个更抽象的概念,任何对象,如果它的类有next方法和iter方法返回自己本身。对于 string、list、dict、tuple等这类容器对象,使用for循环遍历是很方便的。在后台for语句对容器对象调 用iter()函数,iter()是python的内置函数。iter()会返回一个定义了next()方法的迭代器对象,它在容器中 逐个访问容器内元素,next()也是python的内置函数。在没有后续元素时,next()会抛出一个 StopIteration异常 2)生成器(Generator)是创建迭代器的简单而强大的工具。它们写起来就像是正规的函数,只是在需 要返回数据的时候使用yield语句。每次next()被调用时,生成器会返回它脱离的位置(它记忆语句最后 一次执行的位置和所有的数据值) 区别:生成器能做到迭代器能做的所有事,而且因为自动创建了iter()和next()方法,生成器显得特别简洁, 而且生成器也是高效的,使用生成器表达式取代列表解析可以同时节省内存。除了创建和保存程序状态 的自动方法,当发生器终结时,还会自动抛出StopIteration异常 问题 Q2:迭代器和生成器的区别?可用的回答 : 1)迭代器是一个更抽象的概念,任何对象,如果它的类有next方法和iter方法返回自己本身。对于 string、list、dict、tuple等这类容器对象,使用for循环遍历是很方便的。在后台for语句对容器对象调 用iter()函数,iter()是python的内置函数。iter()会返回一个定义了next()方法的迭代器对象,它在容器中 逐个访问容器内元素,next()也是python的内置函数。在没有后续元素时,next()会抛出一个 StopIteration异常 2)生成器(Generator)是创建迭代器的简单而强大的工具。它们写起来就像是正规的函数,只是在需 要返回数据的时候使用yield语句。每次next()被调用时,生成器会返回它脱离的位置(它记忆语句最后 一次执行的位置和所有的数据值) 区别:生成器能做到迭代器能做的所有事,而且因为自动创建了iter()和next()方法,生成器显得特别简洁, 而且生成器也是高效的,使用生成器表达式取代列表解析可以同时节省内存。除了创建和保存程序状态 的自动方法,当发生器终结时,还会自动抛出StopIteration异常 问题 Q3:请用代码简答实现stack?可用的回答 : stack的实现代码(使用python内置的list),实现起来是非常的简单,就是list的一些常用操作 class Stack(object): def _init_(self): self.stack = def push(self, value): # 进栈 self.stack.append(value) def pop(self): #出栈 if self.stack: self.stack.pop() else: raise LookupError(stack is empty!) def is_empty(self): # 如果栈为空 return bool(self.stack) def top(self): #取出目前stack中最新的元素 return self.stack-1 问题 Q4:提到Python中局部变量和全局变量的规则是什么?可用的回答 :局部变量:如果在函数体内的任何位置为变量赋值,则假定它是本地的。全局变量:仅在函数内引用的那些变量是隐式全局变量。问题 Q5:如何在Flask中访问会话?可用的回答 :会话基本上允许您记住从一个请求到另一个请求的信息。在一个Flask中,它使用签名cookie,以便用户可以查看会话内容并进行修改。如果只有密钥Flask.secret_key,则用户可以修改会话。问题 Q6:说一说redis-scrapy中redis的作用?可用的回答 : 它是将scrapy框架中Scheduler替换为redis数据库,实现队列管理共享。 优点: 可以充分利用多台机器的带宽; 可以充分利用多台机器的IP地址。 问题 Q7:什么是Python?使用Python有什么好处?可用的回答 :Python是一种编程语言,包含对象,模块,线程,异常和自动内存管理。Python的好处在于它简单易用,可移植,可扩展,内置数据结构,并且它是一个开源的。问题 Q8:什么是反射?以及应用场景?可用的回答 : 通过字符串获取对象的方法称之为反射 python中可以通过如下方法实现: 1. getattr 获取属性 2. setattr 设置属性 3. hasattr 属性是否存在 4. delattr 删除属性 问题 Q9:写爬虫使用多进程好,还是用多线程好?可用的回答 : IO密集型代码(文件处理、网络爬虫等), 多线程能够有效提升效率(单线程下有IO操作会进行IO等待,造成不必要的时间浪费,而开启多线程能在线程A等待时,自动切换到线程B,可以不浪费CPU的资源,从而能提升程序执行效率)。 在实际的数据采集过程中,既考虑网速和响应的问题,也需要考虑自身机器的硬件情况,来设置多进程或多线程 问题 Q10:你对Django的认识?可用的回答 : Django是走大而全的方向,它最出名的是其全自动化的管理后台:只需要使用起ORM,做简单的对象定义,它就能自动生成数据库结构、以及全功能的管理后台。 Django内置的ORM跟框架内的其他模块耦合程度高。 应用程序必须使用Django内
此题为判断题(对,错)。
A.创建一个返回值列表的函数,它返回给定用户的登录时间值
B.创建一个返回值列表的函数,它返回返回超过当前用户登录时长的那些用户的登录小时数
C.创建一个返回指定用户当天登录小时数的函数
D.创建一个返回指定用户当月登录小时数的函数
已知bead指向一个带头结点的单向链表,链表中每个结点包含数据域(data)和指针域(next),数据域为整型。以下函数求出链表中所有连接点数据域的和值作为函数值返回。请在横线处填入正确内容。
{ int data; struct link *next;}
main()
{ struct link *head;
sam(______);
{stmct link *p;int s=0;
p=head->next;
while(p){s+=p->data;p=p->next;}
return(s);}
阅读下列说明和C代码,将应填入(n)处的字句写在对应栏内。
【说明】
本题给出四个函数,它们的功能分别是:
1.int push(PNODE*top,int e)是进栈函数,形参top是栈顶指针的指针,形参e是入栈元素。
2.int pop(PNODE*top,int*e)是出栈函数,形参top是栈顶指针的指针,形参e作为返回出栈元素使用。
3.int enQueue(PNODE*tail,int e)是入队函数,形参tail是队尾指针的指针,形参e是入队元素。
4.int deQueue(PNODE*tail,int*e)是出队函数,形参tail是队尾指针的指针,形参e作为返回出队元素使用。
以上四个函数中,返回值为。表示操作成功,返回值为-1表示操作失败。
栈是用链表实现的;队是用带有辅助结点(头结点)的单向循环链表实现的。两种链表的结点类型均为:
typedef struct node {
int value;
struct node * next;
} NODE, * PNODE;
【函数1】
int push(PNOOE * top,int e)
{
PNODE p = (PNODE) malloc (sizeof (NODE));
if (! p) return-1;
p->value=e;
(1);
*top=p;
return 0;
}
【函数2】
int pop (PNODE * top,int * e)
{
PNODE p = * top;
if(p == NULL) return-1;
* e = p->value;
(2);
free(p);
return 0;
}
【函数3】
int enQueue (PNODE * tail,int e)
{ PNODE p,t;
t= *tail;
p = (PNODE) malloc(sizeof(NODE));
if(!p) return-1;
p->value=e;
p->next=t->next;
(3);
* tail = p;
return 0;
}
【函数4】
int deQueue(PNODE * tail,int * e)
{ PNODE p,q;
if(( * tail)->next == * tail) return-1;
p= (* tail)->next;
q = p ->next;
* e =q ->value;
(4)=q->next;
if(,tail==q) (5);
free(q);
return 0;
}
阅读以下说明和C语言函数,将应填入(n)。
【说明】
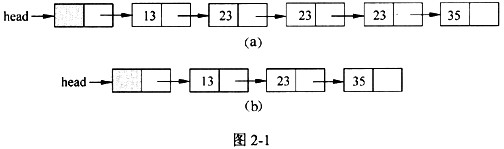
已知包含头结点(不存储元素)的单链表的元素已经按照非递减方式排序,函数 compress(NODE*head)的功能是去掉其中重复的元素,使得链表中的元素互不相同。
处理过程中,当元素重复出现时,保留元素第一次出现所在的结点。
图2-1(a)、(b)是经函数compress()处理前后的链表结构示例图。
链表的结点类型定义如下:
typedef struct Node{
int data;
struct Node *next;
}NODE;
【C语言函数】
void compress(NODE *head)
{ NODE *ptr,*q;
ptr= (1); /*取得第一个元素结点的指针*/
while( (2)&& ptr->next) {
q=ptr->next;
while(q&&(3)) { /*处理重复元素*/
(4)q->next;
free(q);
q=ptr->next;
}
(5) ptr->next;
}/*end of while */
}/*end of compress*/