
已知样本数据1,0,6,1,2,下列说法不正确的是()
第1题:
一个样本由n个观测值组成,已知样本均值X的样本标准差S皆为正数,如果每个观测值扩大到3倍,则下列说法正确的是( )。
A.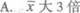
B.
C.
D.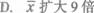
第2题:
关于总体和样本,下列说法中不正确的是
A.总体是根据研究目的确定的
B.总体均为同质
C.总体是所有观察单位的所有变量值的集合
D.样本是从总体中随机抽取的
E.可以用样本信息推断总体特征
第3题:
已知样本A有十个元素,样本B是样本A中每个元素减去100得到的,则以下关于样本A和样本B的说法成立的是( )。
A.样本A和样本B的均值相同
B.样本A和样本B的均值相差100
C.样本A和样本曰的标准差相同
D.样本A和样本B的标准差相差100
第4题:
第5题:
第6题:
一个样本由n个观测值组成,已知样本均值 和样本标准差皆为正数,如果每个观测值增加常数a(a>0),则下列说法正确的是( )。
和样本标准差皆为正数,如果每个观测值增加常数a(a>0),则下列说法正确的是( )。
A.和S都增加常数a
B.和S都不变
C.增加a,S减少a
D.增加,S不变
第7题:
 判断下列说法不正确的是:
判断下列说法不正确的是:

第8题:
样本均数与已知总体均数比较的t检验,其检验假设是
A、假设样本均数与已知总体均数相等
B、假设样本的总体均数与已知总体均数相等
C、样本的总体均数与已知总体均数不相等
D、两个总体均数不相等
E、以上均不正确
第9题:
第10题: