
A.ROBOTSTXT_OBEY
B.ROBOTSTXT_JUDGE
C.ROBOTSTXT
D.ROBOTSTXT_IF
A.spiders文件夹
B.item.py
C.pipeline.py
D.settings.py
A、SCHEDULER=Scrapy-redisschedulerSchedule
B、SCHEDULER='SCRAPYschedulerScheduleCDUPEFILTER_
C、LASSscrap_redis.dupefilterRfpdupefilter
D、dupefilter-class=scrap.dupefilterRfpdupefilter'
A、CPU利用率高
B、线程运行过程中没有线程切换
C、避免了线程间同步时间因调度问题延长
D、把进程所需要的CPU一次性分给进程
A.运行进程修改程序状态字
B.中断屏蔽
C.系统调用
D.进程调度程序
北京京东叁佰陆拾度电子商务有限公司1月招聘面试题面试题面试官常问到的一些题目整理如下:问题 Q1:一行代码实现1-100之和?可用的回答 :使用sum函数。sum(range(1, 101)问题 Q2:写爬虫使用多进程好,还是用多线程好?可用的回答 : IO密集型代码(文件处理、网络爬虫等), 多线程能够有效提升效率(单线程下有IO操作会进行IO等待,造成不必要的时间浪费,而开启多线程能在线程A等待时,自动切换到线程B,可以不浪费CPU的资源,从而能提升程序执行效率)。 在实际的数据采集过程中,既考虑网速和响应的问题,也需要考虑自身机器的硬件情况,来设置多进程或多线程 问题 Q3: scrapy分为几个组成部分?分别有什么作用?可用的回答 : 分为5个部分; 1. Spiders(爬虫类) 2. Scrapy Engine(引擎) 3. Scheduler(调度器) 4. Downloader(下载器) 5. Item Pipeline(处理管道) 具体来说: Spiders:开发者自定义的一个类,用来解析网页并抓取指定url返回的内容。 Scrapy Engine:控制整个系统的数据处理流程,并进行事务处理的触发。 Scheduler:接收Engine发出的requests,并将这些requests放入到处理列队中,以便之后engine需要时再提供。 Download:抓取网页信息提供给engine,进而转发至Spiders。 Item Pipeline:负责处理Spiders类提取之后的数据。 比如清理HTML数据、验证爬取的数据(检查item包含某些字段)、查重(并丢弃)、将爬取结果保存到数据库中 问题 Q4:urllib 和 urllib2 的区别?可用的回答 : urllib 和urllib2都是接受URL请求的相关模块, 但是urllib2可以接受一个Request类的实例来设置URL请求的headers, urllib仅可以接受URL。urllib不可以伪装你的User-Agent字符串。 urllib提供urlencode()方法用来GET查询字符串的产生,而urllib2没有。 这是为何urllib常和urllib2一起使用的原因。 问题 Q5:深拷贝和浅拷贝有什么区别?可用的回答 :在创建新实例类型时使用浅拷贝,并保留在新实例中复制的值。浅拷贝用于复制引用指针,就像复制值一样。这些引用指向原始对象,并且在类的任何成员中所做的更改也将影响它的原始副本。浅拷贝允许更快地执行程序,它取决于所使用的数据的大小。深拷贝用于存储已复制的值。深拷贝不会将引用指针复制到对象。它引用一个对象,并存储一些其他对象指向的新对象。原始副本中所做的更改不会影响使用该对象的任何其他副本。由于为每个被调用的对象创建了某些副本,因此深拷贝会使程序的执行速度变慢。问题 Q6: scrapy的优缺点?为什么要选择scrapy框架?可用的回答 : 优点: 采取可读性更强的xpath代替正则强大的统计和log系统 同时在不同的url上爬行 支持shell方式,方便独立调试 写middleware,方便写一些统一的过滤器 通过管道的方式存入数据库 缺点: 基于python爬虫框架,扩展性比较差,基于twisted框架, 运行中exception是不会干掉reactor,并且异步框架出错后是不会停掉其他任务的,数据出错后难以察觉 问题 Q7:创建一个简单tcp服务器需要的流程?可用的回答 : 1.socket创建一个套接字 2.bind绑定ip和port 3.listen使套接字变为可以被动链接 4.accept等待客户端的链接 5.recv/send接收发送数据 问题 Q8:描述数组、链表、队列、堆栈的区别?可用的回答 : 数组与链表是数据存储方式的概念,数组在连续的空间中存储数据,而链表可以在非连续的空间中存储数据; 队列和堆栈是描述数据存取方式的概念,队列是先进先出,而堆栈是后进先出; 队列和堆栈可以用数组来实现,也可以用链表实现。 问题 Q9:简述 yield和yield from关键字?可用的回答 : 1、可迭代对象与迭代器的区别 可迭代对象:指的是具备可迭代的能力,即enumerable. 在Python中指的是可以通过for-in 语句去逐个访问元素的一些对象,比如元组tuple,列表list,字符串string,文件对象file 等。 迭代器:指的是通过另一种方式去一个一个访问可迭代对象中的元素,即enumerator。 在python中指的是给内置函数iter()传递一个可迭代对象作为参数,返回的那个对象就是迭代器,然后通过迭代器的next()方法逐个去访问。 问题 Q10:.什么是关联查询,有哪些?可用的回答 :将多个表联合起来进行查询,主要有内连接、左连接、右连接、全连接(外连接)算法题面试官常问到的一些算法题目整理如下(大概率会机考):算题题 A1:3D图形的表面区域题目描述如下:Contest 1:On a N * N grid, we place some 1 * 1 * 1 cubes.Each value v = gridij represents a tower of v cubes placed on top of grid cell (i, j).Return the total surface area of the resulting shapes. Example 1:Input: 2Output: 10Example 2:Input: 1,2,3,4Output: 34Example 3:Input: 1,0,0,2Output: 16Example 4:Input: 1,1,1,1,0,1,1,1,1Output: 32Example 5:Input: 2,2,2,2,1,2,2,2,2Output: 46 Note:1 = N = 500 = gridij = 50每个叠起来的正方体面数有6 * x - 2 * (x-1)个。确定好上下左右每个被覆盖的面减去即可。可做参考的解答如下:class Solution(object): def surfaceArea(self, grid): :type grid: ListListi
下面关于进程、线程的说法正确的是()。
A.进程是程序的一次动态执行过程。一个进程在其执行过程中,可以产生多个线程——多线程,形成多条执行线索
B.线程是比进程更小的执行单位,是在一个进程中独立的控制流,即程序内部的控制流。线程本身不能自动运行,栖身于某个进程之中,由进程启动执行
C.Java多线程的运行与平台相关
D.对于单处理器系统,多个线程分时间片获取CPU或其他系统资源来运行。对于多处理器系统,线程可以分配到多个处理器中,从而真正的并发执行多任务
在多处理系统中,进程调度用来决定哪个进程得到CPU的控制。调度分为三个阶段:长期,中期,短期。长期调度是指(15)。属于中期调度增加的进程状态是(16)。下面关于短期调度说法正确的是(17)。
A.调度程序把CPU分配给已装入主存储准备运行的进程
B.把进程调人/调出主存储器
C.决定哪些作业或进程可以竞争系统资源
D.决定哪些线程共享存储器
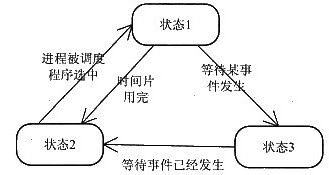
阅读下列说明和图表,回答问题1到问题3。
[说明]
在多道程序系统中,各个程序之间是并发执行的,共享系统资源。CPU需要在各个运行的程序之间来回地切换,这样的话,要想描述这些多道的并发活动过程就变得很困难。为此,操作系统设计者提出了进程的概念。
进程是具有独立功能的程序关于某个数据集合上的一次动态执行过程,是系统进行资源分配和调度的独立单位。
进程在生命消亡前处于且仅处于三种基本状态之一。运行态(Running):进程占有CPU,并在CPU上运行。就绪态(Ready):一个进程已经具备运行条件,但由于无CPU暂时不能运行的状态(当调度给其CPU时,立即可以运行)。等待态(Blocked):指进程因等待某种事件的发生而暂时不能运行的状态,即使CPU空闲,该进程也不可运行。指出如下进程状态转换图(图4-1)中“状态1”~“状态3”分别是什么状态。
[图4-1]
A.避免CPU周期的浪费
B.可以提高效率
C.可以最大限度使用CPU资源
D.符合面向过程编程思想
以下叙述正确的是
A.进程的优先级分为一般优先级和特殊优先级两种
B.时间片 (Time-slice)是一段时间,一般为几秒到几百秒
C.Windows系统中由CPU负责线程调度、中断处理等等
D.在单线程系统中调度对象是进程,在多线程系统中调度对象是线程